Второе место «КОД науки» в номинации
«Технические науки и искусственный интеллект» (2026 г.)
Аннотация. В статье рассматривается развитие архитектур интеллектуальных ассистентов в образовательных системах на примере платформы «НейроЛик» МГПУ. Показано, что на текущем этапе платформа реализует логику retrieval-augmented generation, обеспечивая формирование ответов на основе загруженных пользователем документов и базовой языковой модели. Раскрыты сильные стороны такого решения для учебного консультирования, персонализации взаимодействия и локализации содержания в рамках конкретной предметной области. Одновременно выявлены ограничения RAG-подхода в ситуациях, требующих не только поиска релевантных фрагментов, но и выявления смысловых связей между понятиями, авторами, методами и результатами исследований. На основе анализа современных работ по RAG и GraphRAG, а также изучения возможностей платформы «НейроЛик» МГПУ, предложена модель перехода к графовому представлению знаний. Сформулированы направления интеграции GraphRAG в существующие модули платформы, описаны изменения на уровне обработки документов, диалогового интерфейса и сценариев педагогического применения. Обосновано, что данный переход способен усилить исследовательскую и аналитическую составляющую взаимодействия студентов с интеллектуальными ассистентами, повысить связность работы с научными материалами и расширить возможности поддержки учебной и исследовательской деятельности.
Ключевые слова: интеллектуальные ассистенты, образовательные системы, RAG, GraphRAG, цифровая дидактика, исследовательская деятельность, ИИ-ассистенты.
В последнее время цифровая трансформация высшего образования все больше становится связана не только с расширением набора используемых ресурсов, но и с изменением характера взаимодействия обучающихся с информацией. Если на предыдущих этапах цифровизация преимущественно обеспечивала хранение контента, администрирование учебного процесса и автоматизацию отдельных процедур, то современная образовательная среда все в большей степени включает инструменты интеллектуальной поддержки, которые способны вести диалог, учитывать контекст запроса и опираться на внешние источники знаний. Именно в этой плоскости особое значение приобретают интеллектуальные ассистенты, которые постепенно переходят из статуса экспериментальных сервисов в статус инфраструктурных компонентов образовательной системы.
Вместе с тем сама возможность включения таких ассистентов в образовательный процесс еще не гарантирует их педагогической эффективности. Для научно-практического анализа существенным является не только использование в системе большой языковой модели, но и организация работы со знанием, механизмы, обеспечивающие релевантность ответов, поддержка предметной локализации, а также понимание, в какой мере ассистент способен сопровождать более сложные виды деятельности, чем оперативное консультирование. На этом фоне вопрос об архитектуре интеллектуального ассистента становится не технической деталью, а существенным условием его педагогической состоятельности.
В современной литературе в качестве одного из наиболее продуктивных решений рассматривается retrieval-augmented generation (RAG). В классической постановке RAG связывает параметрическую память языковой модели с внешней непараметрической памятью, представленной индексом документов и механизмом их извлечения по пользовательскому запросу [8]. Благодаря этому модель получает возможность опираться не только на свои внутренние параметры, но и на актуализируемый контекст, что повышает фактическую точность ответов и уменьшает зависимость результата от случайных ассоциаций, характерных для изолированной генерации [10]. Для образовательных систем это имеет принципиальное значение, поскольку именно здесь особенно важны предметная корректность, управляемость и возможность опоры на верифицированный корпус материалов.
Однако по мере расширения задач, решаемых с помощью интеллектуальных ассистентов, стала заметной и ограниченность традиционного RAG-подхода. Он хорошо работает в ситуации локального ответа на конкретный вопрос, но значительно слаб в случаях, когда требуется реконструировать общую структуру темы, выявить смысловые связи между документами, показать отношения между понятиями и научными подходами, подготовить обзор научной литературы или провести проектирование исследования. Данная граница особенно ощутима в университетской среде, где ИИ-ассистент должен помогать студенту не только находить фрагменты информации, но и выстраивать целостную картину предметной области, соотносить теоретические позиции и аргументированно двигаться от темы к научной проблеме [4, 9].
В таком отношении показателен пример платформы «НейроЛик», разработанной Московским городским педагогическим университетом. Согласно руководству пользователя, платформа предназначена для разработки, настройки и эксплуатации интеллектуальных виртуальных агентов в образовании. Каждая ИИ-персона в системе создается на основе технологии RAG и использует загруженные документы как собственную базу знаний. Также предусмотрены специализированные модули для создания персон, прямой работы с моделями, генерации промптов и сравнения нескольких персон [5]. «НейроЛик» позволяет рассматривать не гипотетическую, а реально функционирующую образовательную платформу, в которой архитектура интеллектуального ассистента уже стала предметом практической реализации и может быть проанализирована с точки зрения дальнейшего развития.
Цель исследования состоит в выявлении логики развития архитектур интеллектуальных ассистентов в образовательных системах на примере «НейроЛик» МГПУ, в сравнительном анализе возможностей RAG и GraphRAG и в обосновании модели перехода к графовому представлению знаний как следующему этапу развития платформы.
Исследование носит аналитико-проектный характер и опирается на сочетание нескольких методов. В качестве методологической основы использованы анализ научной литературы по retrieval-augmented generation и GraphRAG, сравнительный анализ архитектур интеллектуальных ассистентов, структурно-функциональное моделирование и содержательный анализ пользовательской документации платформы «НейроЛик» МГПУ. Данный набор методов представляется оправданным, поскольку предметом рассмотрения выступает не отдельная программная функция, а логика развития целостной архитектуры в ее связи с педагогическими задачами.
Литературная база исследования включает работы, в которых RAG рассматривается как средство соединения генеративной языковой модели с внешним корпусом знаний [8], а также более поздние обзоры, фиксирующие эволюцию данного подхода и появление продвинутых, модульных и графовых схем retrieval-архитектур [7], [10]. Для осмысления образовательного контекста использованы современные отечественные и зарубежные публикации, посвященные цифровой трансформации подготовки педагогов, использованию генеративного искусственного интеллекта в высшем образовании и условиям ответственного внедрения ИИ в образовательную среду [1], [2], [3], [4], [9].
Эмпирической основой проектного анализа послужило руководство пользователя платформы «НейроЛик» МГПУ [5]. Именно этот документ дает возможность реконструировать действующую организацию модулей платформы, режимы работы ИИ-персон, особенности загрузки документов, настройки базовой языковой модели и сценарии взаимодействия пользователя с системой. Такая реконструкция важна не только для описания текущего состояния платформы, но и для последующего проектирования точек интеграции GraphRAG в уже существующую инфраструктуру.
В результате используемые методы позволяют решить три взаимосвязанные задачи: зафиксировать текущее состояние платформы как реализации RAG-архитектуры, выявить особенности образовательной практики, для которых возможностей RAG оказывается недостаточно, и на данной основе предложить реалистичную модель дальнейшего архитектурного развития.
Появление RAG стало важным этапом в эволюции генеративных систем, поскольку этот подход выступил продуктивным компромиссом между большой языковой моделью и необходимостью опоры на внешнее, обновляемое и предметно локализованное знание. В исходной работе P. Lewis и соавторов RAG описывается как архитектура, в которой параметрическая память seq2seq-модели дополняется непараметрической памятью в виде плотного векторного индекса, доступ к которому осуществляется с помощью нейронного retriever-механизма [8]. Тем самым модель получает возможность извлекать релевантные документы и использовать их как контекст для ответа.
В прикладном плане это позволило решить несколько принципиальных задач. Во-первых, ответ языковой модели стал в большей степени связан с документальным обоснованием, а не только с распределением вероятностей, сложившимся в процессе предобучения. Во-вторых, оказалось возможным обновлять знания системы без повторного обучения самой модели, заменяя или расширяя внешний корпус данных. В-третьих, увеличилась объяснимость результата, поскольку retrieval-контур в определенной мере делает прозрачным, из какого содержательного материала формировался ответ. По этой причине RAG быстро стал базовой архитектурой во многих прикладных системах, ориентированных на работу с корпоративными, учебными, исследовательскими и институциональными массивами документов [10].
Для образовательной среды преимущества RAG особенно заметны. В отличие от универсального чат-сервиса, действующего на основе общей языковой модели, RAG-ассистент может быть привязан к учебной дисциплине или курсу, нормативному документу, локальной методической базе или научному корпусу. Это позволяет выстраивать более управляемое взаимодействие со студентом, уменьшить риск фактических неточностей и локализовать содержание ответа в рамках конкретной образовательной задачи. В результате интеллектуальный ассистент начинает функционировать не как абстрактный собеседник, а как цифровой посредник между пользователем и выбранным массивом знаний.
В то же время сама логика RAG остается преимущественно текстоцентричной. Ее базовая единица – документ или фрагмент документа, извлеченный по признаку семантической релевантности. Отсюда вытекает и главное ограничение: система хорошо отвечает на частный вопрос, если в корпусе присутствуют нужные материалы, но она не всегда способна реконструировать структуру самой предметной области. Иначе говоря, retrieval-контур обеспечивает доступ к знаниям, но не обязательно поддерживает их концептуальную организацию. Данный недостаток долгое время не был критичным для консультационных сценариев, но стал особенно заметным по мере перехода интеллектуальных ассистентов от справочной функции к поддержке аналитической и исследовательской деятельности студентов.
Руководство пользователя платформы «НейроЛик» МГПУ позволяет достаточно подробно зафиксировать, каким образом RAG реализован в конкретной образовательной системе. Платформа позиционируется как web-ориентированная среда для разработки, настройки и эксплуатации виртуальных агентов в образовании. После авторизации пользователь получает доступ к нескольким модулям, среди которых ключевыми для анализа архитектуры являются разделы «Все персоны», «Мои персоны», «ИИ-инструменты», «Промптопомощник» и «Сравнение персон».
На главной странице платформы представлен список ИИ-персон. В руководстве прямо указано, что каждая такая персона является интеллектуальным агентом, созданным на основе технологии RAG и использующим загруженные документы как собственную базу знаний [5]. Данное положение позволяет сделать важный вывод – «НейроЛик» изначально строится не вокруг единственной универсальной модели, а вокруг множества конфигурируемых агентов, каждый из которых может быть связан с собственным содержательным корпусом. Тем самым архитектура платформы ориентирована на персонализацию и предметную локализацию.
Функционал модуля «Мои персоны» конкретизирует представленный вывод. Пользователь может создать новую персону, задать ее название, описание, предметную область и основные параметры. В режиме редактирования доступны выбор большой языковой модели, загрузка документов, формирующих базу знаний, настройка видимости, редактирование приветствия и системного промпта. Допускается загрузка не более двадцати файлов в формате .docx, при этом размер каждого файла не должен превышать 20 МБ. После загрузки документов система начинает их обработку. Статусы персоны отражают стадии ожидания, обучения, возможной ошибки и готовности к работе [5]. Особенно показательно примечание в руководстве о том, что сразу после создания, еще до загрузки документов, ИИ-персона уже доступна для общения, но ответы будут формироваться только на основе базовой языковой модели, без учета индивидуального контекста и знаний. Это означает, что на платформе представлены два режима: генерация без внешней базы и генерация с retrieval-контуром. Следовательно, действующая архитектура «НейроЛик» соответствует типичной схеме перехода от LLM-only к RAG.
С педагогической точки зрения такая организация дает несколько ощутимых преимуществ. Во-первых, появляется возможность создавать специализированные ИИ-ассистенты для разных дисциплин, курсов, проектов и исследовательских направлений. Во-вторых, сохраняется управляемость содержания: преподаватель или разработчик персоны вносят изменения не в параметры самой модели, а во внешний контур знаний. В-третьих, диалоговый интерфейс делает работу с материалами более естественной для студента, поскольку сведения извлекаются не через поиск по папкам и файлам, а через предметно-ориентированное общение. Дополнительные модули платформы также усиливают данную логику. «ИИ-инструменты» дают доступ к большим языковым моделям без пользовательских настроек и загруженных документов, «Промптопомощник» позволяет генерировать и тестировать промпт-запросы, а модуль сравнения персон обеспечивает одновременное взаимодействие с несколькими агентами [5]. Все это демонстрирует, что «НейроЛик» уже выступает полноценной платформенной средой для проектирования интеллектуальных ассистентов в образовании.
Вместе с тем анализ структуры модулей показывает и обратную сторону. Все ключевые операции платформы сосредоточены вокруг документов, языковой модели и текстового взаимодействия. База знаний формируется как корпус файлов, обработанных системой, а не как карта понятий, сущностей и отношений. Промптопомощник организует работу с запросами, но не с концептуальной структурой темы. Сравнение разработанных ИИ-персон показывает отличия в ответах, но не в организации знания. Иначе говоря, сильные стороны платформы непосредственно вырастают из преимуществ RAG, а ее ограничения – из границ, которые для RAG являются внутренними.
Для корректной оценки перспектив развития платформы важно не только указать на ограничения текущего решения, но и зафиксировать, какие задачи RAG уже успешно решает на платформе. Практика подобных систем показывает, что RAG оказывается особенно эффективным там, где требуется быстрый и содержательно корректный доступ к учебному или методическому материалу. В случае «НейроЛик» это, прежде всего, объяснение терминов, навигация по содержанию дисциплины, консультация по нормативным требованиям, помощь в освоении материалов конкретного курса и предметно-локализованное общение со студентом.
Существенное достоинство платформы состоит и в том, что она позволяет преподавателю перейти от использования универсального генеративного сервиса к созданию собственной ИИ-персоны с заданным профилем знаний и поведения. Это значительно ближе к задачам цифровой дидактики, в которой важны не только доступность инструмента, но и его встраивание в логику курса, профессионального общения, научного руководства и проектной деятельности [1], [2], [3]. В данном отношении «НейроЛик» демонстрирует уже достигнутый уровень зрелости: платформа не сводится к диалогу с «чистой» моделью, а работает как среда настройки цифровых агентов для конкретных образовательных функций.
Однако, по мере перехода к более сложным задачам начинают проявляться и ограничения, вытекающие именно из текстоцентричной организации retrieval-контента. При обращении к ИИ-ассистенту с запросом, связанным не с отдельным термином или локальным фрагментом, а с общим пониманием темы, системой научных подходов, логикой построения обзора литературы или выявлением исследовательской лакуны, RAG уже не всегда обеспечивает достаточную глубину ответа. Система может подобрать релевантные документы, однако не показать, как они внутренне соотносятся между собой.
Для использования ИИ-помощника как учебного консультанта такой подход не всегда является критичным, а в научно-исследовательской деятельности – именно данное отличие становится принципиальным. Студенту важно не просто знать, какие источники относятся к определенной теме, но и понимать, какие подходы в них представлены, как соотносятся понятия, где проходят линии согласия и расхождения в тех или иных подходах, какие методы чаще встречаются в определенном исследовательском поле. При работе с теоретической главой и обзором литературы RAG-ассистент способен помочь найти материалы, но практически не поддерживает задачу по их анализу, в связи с чем возникает риск перечислительности, фрагментарности и механического накопления цитат без достаточного синтеза. Пользователь может общаться с ИИ-персоной, тестировать промпты или сопоставлять ответы, но не получает встроенного механизма, который бы переводил ассистента из режима «ответа по документам» в режим «анализа структуры темы». Следовательно, дальнейшее развитие платформы закономерно должно быть связано не с заменой RAG, а с его расширением в сторону архитектур, способных работать со знанием как с системой отношений.
Одним из наиболее перспективных направлений такого развития в настоящее время выступает GraphRAG, который вводит дополнительный уровень структурирования знания. В работе D. Edge и соавторов GraphRAG описан как «графовый подход к ответам на запросы по частным текстовым корпусам, основанный на извлечении графа сущностей и отношений, построении иерархии сообществ и предварительном формировании их суммарных описаний» [6], что позволяет системе отвечать не только на локальные запросы, но и на так называемые глобальные вопросы, требующие обобщения, выявления тем и реконструкции смысловой организации корпуса.
Обзор H. Han и соавторов показывает, что включение графов в retrieval-архитектуры превращает их из инструмента поиска дополнительной информации в инструмент работы с гетерогенными и реляционными данными [7]. Для образовательной среды это означает существенное изменение характера интеллектуальной поддержки. Если RAG помогает студенту получить релевантный фрагмент, то GraphRAG может помочь увидеть, какие понятия и авторы образуют смысловые кластеры, как распределяются исследовательские линии, где имеются связующие и периферийные элементы, а также как локальный запрос соотносится с общей структурой предметной области. В этом отношении GraphRAG не следует понимать как «более модную» замену RAG. Напротив, корректнее рассматривать его как архитектурное развитие retrieval-подхода. Он сохраняет сильную сторону RAG – опору на внешний корпус документов, но дополняет ее уровнем структурно-семантической обработки. Следовательно, речь идет не о противопоставлении двух взаимоисключающих решений, а о переходе от текстового retrieval к более глубокому представлению знания.
Для платформы НейроЛик МГПУ – это особенно важно, поскольку ее дальнейшая ценность связана не только с качеством ответов, но и с возможностью сопровождать учебную и исследовательскую деятельность. В контексте университета интеллектуальный ассистент постепенно становится не просто сервисом оперативной помощи, а инструментом формирования академических способов работы с информацией. Именно поэтому переход к GraphRAG следует оценивать не только по вычислительной эффективности, но и по педагогическому потенциалу.
Сравнительный анализ архитектур RAG и GraphRAG показывает, что отличие между ними заключается не только в уровне технической сложности, но и также связано с более фундаментальным различием организации знания внутри интеллектуального ассистента. В первом случае базовой единицей выступает текстовый фрагмент, связанный с запросом пользователя через семантическую близость. Во втором – сущность, отношение, тематическое сообщество или подграф, которые позволяют системе работать не только с документом как таковым, но и с внутренней конфигурацией предметной области. GraphRAG способен не только улучшить ответы на сложные запросы, но и изменить сам характер платформенной поддержки: от локального retrieval к аналитической навигации по массиву знаний (см. таблицу 1). Рисунок 1 отражает общую логику перехода от генерации без внешней базы к RAG, а затем к GraphRAG. Если первая стадия обеспечивает лишь опору на параметрическую память модели, вторая – на документы и их фрагменты, то третья добавляет граф знаний и иерархию сообществ. В результате архитектурное развитие можно интерпретировать как движение от ответа «по вероятности» к ответу «по документу», а затем – к ответу «по структуре знания».
Таблица 1. Сопоставление архитектур RAG и GraphRAG применительно к платформе «НейроЛик» МГПУ
|
Параметр |
RAG |
GraphRAG |
Значение для «НейроЛик» МГПУ |
|
Базовая единица знаний |
Документ или его фрагмент. |
Сущность, отношение, сообщество, подграф. |
Переход от работы с файлами к работе со структурой предметной области. |
|
Логика поиска |
Семантическое сходство фрагментов. |
Поиск по связям, кластерам и суммарным описаниям. |
Поддержка не только локальных ответов, но и обзора темы. |
|
Тип ответа |
Локально релевантный ответ по найденным материалам. |
Локально и глобально связанный ответ. |
Возможность развести консультационный и аналитический режимы. |
|
Работа со смысловыми связями |
Преимущественно неявная. |
Явная и структурированная. |
Поддержка выявления отношений между понятиями, авторами и методами. |
|
Педагогическая функция |
Информационная и консультативная поддержка. |
Аналитическая и исследовательская поддержка. |
Усиление работы над обзором литературы и проектированием исследования. |
|
Инфраструктурная сложность |
Относительно умеренная. |
Более высокая. |
Требует поэтапного внедрения и настройки корпуса данных. |
|
Оптимальные сценарии |
Ответы по документам, навигация, уточнение терминов. |
Картирование темы, поиск лакун, сравнение линий исследований. |
Расширяет существующие модули персон, сравнения и промптопомощника. |
Сопоставление различий в способе организации знаний дополнительно отражено на рисунке 2.
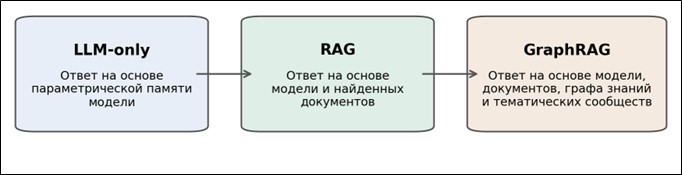
Рис. 1. Эволюция архитектур интеллектуальных ассистентов в образовательной системе
Мы видим, что в RAG ключевую роль играет переход от запроса к релевантным фрагментам документов, тогда как в GraphRAG между корпусом и ответом возникает дополнительный уровень – граф сущностей, отношений и тематических сообществ. Для платформы «НейроЛик» данная разница означает переход от ответа по найденным текстам к ответу, опирающемуся на карту предметной области.
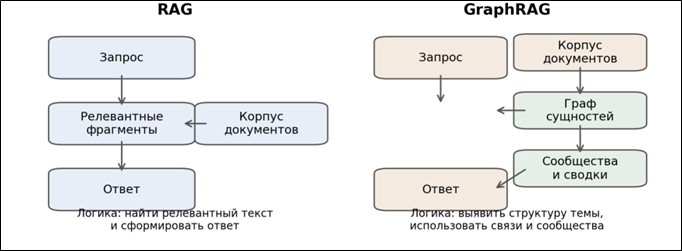
Рис. 2. Сравнительная модель организации знаний в RAG и GraphRAG
С учетом действующей архитектуры платформы переход к GraphRAG целесообразно проектировать не как полную замену существующих модулей, а как их последовательное расширение. «НейроЛик» МГПУ уже содержит необходимые точки входа для такого расширения: загрузка документов, выбор модели, настройка ИИ-персоны, модуль сравнения и инструменты промптовой работы [5]. Следовательно, задача состоит в добавлении нового слоя обработки знаний и в изменении пользовательских сценариев, а не в перестройке платформы с нуля.
На первом этапе после загрузки документов система должна не только индексировать их для последующего извлечения, но и изымать из них сущности, отношения и описания. В образовательном и исследовательском контексте такими сущностями могут выступать понятия, авторы, методы, типы данных, исследовательские проблемы, возрастные категории, темы учебных занятий, образовательные результаты, технологические инструменты. Далее из полученного множества элементов формируется граф знаний, который становится вторым содержательным контуром ИИ-персоны наряду с традиционным векторным индексом документов.
На втором этапе необходимо организовать уровень тематической кластеризации и иерархии сообществ, что позволит не просто хранить связи между отдельными сущностями, но и собирать их в более крупные смысловые образования. Для пользователя такая работа системы должна проявляться не в демонстрации технических деталей графа, а в появлении новых режимов ответа: например, «обзор темы», «ключевые линии исследований», «связи между понятиями», «чего не хватает в корпусе», «как связаны объект, предмет и методы». Иначе говоря, GraphRAG должен входить в интерфейс платформы через педагогически понятные эффекты.
На третьем этапе следует расширить диалоговый интерфейс. В текущей архитектуре пользователь обращается к ИИ-персоне с вопросом и получает ответ, опирающийся на документы. После внедрения GraphRAG имеет смысл развести по крайней мере два сценария. Первый – «ответ по документам», который сохраняет преимущества классического RAG и нужен для быстрых консультационных обращений. Второй – «аналитический режим», активирующий графовый контур и позволяеющий системе работать с темой на более высоком уровне обобщения. В этом случае студент может получить не только ответ, но и схему смысловых связей, перечень центральных узлов темы и указание на содержательные лакуны.
Особое значение переход к GraphRAG имеет для модуля «Промптопомощник». Сейчас он генерирует и тестирует промпты по заданным параметрам [5]. После интеграции графового слоя модуль способен стать средством проектирования последовательности исследовательских вопросов. Например, система может сначала предложить запросы на выявление ключевых понятий темы, затем – на группировку литературных источников, далее – на сравнение научных позиций, после перейти к выделению методологических противоречий и, наконец, сформулировать исследовательскую проблему. Такой маршрут не сводится к отдельному промпту, а становится цифровой поддержкой исследовательской логики.
Не менее перспективно расширение модуля сравнения персон. В существующей реализации он дает возможность одновременно обращаться к нескольким ИИ-персонам. После включения GraphRAG модуль сравнения можно использовать для сопоставления не только готовых ответов, но и самих карт знания, характерных для разных персон, что открывает дополнительный дидактический ресурс: студент или преподаватель сможет видеть отличия не только формулировки ответа, но и способы структурирования предметной области.
Рисунок 3 демонстрирует, что GraphRAG не отменяет текущий retrieval-контур, а надстраивается над ним. Документы, загруженные в платформу, одновременно становятся источником для векторного индекса и для извлечения сущностей. В результате «НейроЛик» МГПУ получает двухконтурную архитектуру, в которой локальные запросы по-прежнему обслуживаются через RAG, а аналитические и обобщающие – через графовый слой.
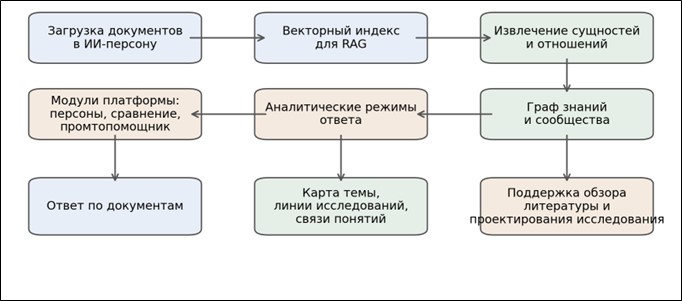
Рис. 3. Модель интеграции GraphRAG в платформу НейроЛик МГПУ
Для перехода от проектного решения к доказательному внедрению необходима специальная программа апробации. Ее целесообразно строить не только вокруг качества генерируемого ответа, но и вокруг образовательных результатов, которые сопровождают использование платформы. В случае «НейроЛик» такими результатами могут выступать качество обзора литературы, степень логической связности текста, глубина аналитического сопоставления источников, корректность формулирования проблемы исследования и способность студента аргументировать выбор методов.
С рассматриваемой точки зрения сравнение RAG и GraphRAG следует выстраивать в рамках близких по содержанию сценариев. Например, одна группа студентов может использовать традиционный режим ИИ-персоны на основе RAG, а другая – режим с подключенным графовым слоем. При этом оцениваться должны не только удобство работы и субъективная удовлетворенность, но и структура итогового текста, характер используемых связок между понятиями, полнота охвата тематических кластеров, снижение доли описательного пересказа и рост самостоятельности в аналитическом осмыслении материала. Такая логика оценки соответствует требованию доказательной педагогики, в которой эффективность цифрового средства устанавливается через измеримые изменения в учебной или исследовательской деятельности [3], [4].
С практической позиции платформа «НейроЛик» МГПУ предоставляет удобную основу для подобной апробации, поскольку в ней уже существуют модули настройки персон, сравнения и тестирования промптов [5]. Это означает, что экспериментальная проверка может проводиться без радикального изменения общей среды. Более того, сам процесс перехода к GraphRAG может быть организован поэтапно: сначала как прототип для отдельных персон и исследовательских сценариев, затем как опциональный аналитический режим, и лишь после этого – как устойчивый компонент платформенной архитектуры. Подобная стратегия снижает организационные риски и позволяет сопоставлять эффекты разных архитектур не абстрактно, а в рамках одной и той же образовательной экосистемы.
Проведенный анализ показывает, что развитие архитектур интеллектуальных ассистентов в образовательных системах закономерно проходит несколько этапов. Сначала генеративная модель функционирует как относительно автономный инструмент ответа на запросы. Затем к ней подключается retrieval-контур, позволяющий опираться на внешние документы и тем самым локализовать знания в рамках предметной области. Следующий этап связан с переходом к более сложным архитектурам, в которых система работает уже не только с текстовыми фрагментами, но и со структурой знаний как сетью сущностей и отношений.
Платформа «НейроЛик» МГПУ представляет собой яркий пример действующей образовательной системы, в которой этап RAG уже реализован на прикладном уровне. Использование ИИ-персон, настраиваемых с помощью загружаемых документов, системного промпта и выбора базовой модели, обеспечивает качественную предметную локализацию и делает платформу полезной для консультационных и учебных сценариев. Вместе с тем возможности этой архитектуры оказываются ограниченными в тех ситуациях, где студенту необходимо не только получить ответ, но и выстроить содержательные связи между источниками, понятиями, методами и направлениями анализа.
Именно поэтому переход к GraphRAG представляется для «НейроЛик» не внешним усложнением, а внутренне подготовленным этапом развития. Введение графового представления знаний, иерархии тематических сообществ и новых аналитических режимов ответа способно существенно усилить исследовательскую и образовательную ценность платформы. В этом случае интеллектуальный ассистент перестает быть только средством retrieval-поддержки и превращается в инструмент сопровождения аналитического и исследовательского мышления.
Практическая значимость предложенной модели состоит в том, что она соотнесена с уже существующими модулями платформы и может быть реализована поэтапно: через расширение обработки базы знаний, диалогового интерфейса, промптопомощника и режима сравнения персон.
Рис. 4. Эволюция ИИ-ассистентов: от RAG к GraphRAG в образовании (на примере «Нейролик» МГПУ) (Создано с помощью нейросети)
Таким образом, дальнейшее развитие «НейроЛик» МГПУ целесообразно связывать с движением от retrieval-ориентированной архитектуры к архитектуре структурированного знания, в которой интеллектуальный ассистент выступает не только средством доступа к информации, но и средством ее педагогически организованного осмысления (рис. 4).
Список литературы:
- Абрамов В.И. Искусственный интеллект в образовании: направления применения и ограничения / В.И. Абрамов, А.В. Гриншкун, А.В. Елисеев, Н.С. Корнева, Т.Н. Суворова // Современная цифровая дидактика. М.: А-Приор, 2023. С. 89-98.
- Гриншкун В.В., Суворова Т.Н. Особенности подготовки педагогов в условиях цифровой трансформации системы образования // Вестник Московского университета. Серия 20: Педагогическое образование, 2024. Т. 22, №1. С. 95-110.
- Гриншкун В.В., Суворова Т.Н., Шунина Л.А. О необходимости формирования цифровой образовательной среды для подготовки будущих педагогов // Известия Российской академии образования, 2024.№ 3(67). С. 162-180.
- Кошкина Е.А. Генеративный искусственный интеллект в высшем образовании: обзор теоретических подходов и практик применения / Е.А. Кошкина, Н.В. Бордовская, Д.С. Гнедых, М.А. Хромова, Р.В. Демьянчук, М.П. Исхакова, П.А. Балышев // Высшее образование в России, 2025. Т. 34, №6. С. 36-57.
- Руководство пользователя «ИИ-платформа по созданию виртуальных агентов в образовании». М.: 19 с.
- Edge D. From Local to Global: A Graph RAG Approach to Query-Focused Summarization / D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, J. Larson // arXiv. 2024. arXiv:2404.16130.
- Han H. Retrieval-Augmented Generation with Graphs (GraphRAG) / H. Han, Y. Ding, C. Liu et al. // arXiv. 2025. arXiv:2501.00309.
- Lewis P. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks / P. Lewis, E. Perez, A. Piktus et al. // arXiv. 2020. arXiv:2005.11401.
- Miao F., Holmes W. Guidance for Generative AI in Education and Research. Paris: UNESCO, 2023.
- Wu S. Retrieval-Augmented Generation for Natural Language Processing: A Survey / S. Wu, Y. Zhang, F. Fei et al. // arXiv. 2024. arXiv:2407.13193.
Development of intelligent assistant architectures in education based on NeuroLik-MGPU
Eliseev A.V.,
postgraduate student of 3 course of the Moscow City University, Moscow
Coauthor:
Ryabikova D.L.,
postgraduate student of 1 course of the Moscow City University, Moscow
Research supervisor:
Grinshkun Vadim Valerevich,
Professor, Department of Informatization of Education, Institute of Digital Education, Moscow City University, Academician of the Russian Academy of Education, Doctor of Pedagogical Sciences, Professor
Abstract. The article examines the development of intelligent assistant architectures in educational systems using the NeuroLik-MGPU platform as a case study. It shows that the current platform relies on retrieval-augmented generation and produces responses on the basis of uploaded documents and a base language model. The strengths of this approach for subject-specific consulting, personalization and contextual relevance are identified, while its limitations are revealed in tasks that require not only retrieval of relevant fragments but also explicit representation of relations among concepts, authors, methods and research results. Based on an analysis of current studies on RAG and GraphRAG and on the functionality of NeuroLik-MGPU, the paper substantiates a transition to graph-based knowledge representation. A model for integrating GraphRAG into the existing modules of the platform is proposed, including changes in document processing, dialog interface and pedagogical scenarios. It is argued that such a transition can strengthen students’ analytical and research-oriented interaction with intelligent assistants and expand the platform’s capacity to support both learning and research activities.
Keywords: intelligent assistants, educational systems, RAG, GraphRAG, digital didactics, research activity, AI-assistants.
References:
- Abramov V.I. Artificial intelligence in education: directions of application and restrictions / V.I. Abramov, A.V. Grinshkun, A.V. Eliseev, N.S. Korneva, T.N. Suvorova//Modern digital didactics. Moscow: A-Prior, 2023.: 89-98.
- Grinshkun V.V., Suvorova T.N. Features of teacher training in the context of digital transformation of the education system//Bulletin of Moscow University. Series 20: Teacher Education, 2024. Vol. 22, №1.: 95-110.
- Grinshkun V.V., Suvorova T.N., Shunina L.A. On the need to form a digital educational environment for the training of future teachers//Izvestia of the Russian Academy of Education, 2024. №3(67).: 162-180.
- Koshkina E.A. Generative artificial intelligence in higher education: a review of theoretical approaches and application practices / E.A. Koshkina, N.V. Bordovskaya, D.S. Gnedykh, M.A. Khromova, R.V. Demyanchuk, M.P. Iskhakova, P.A. Balyshev // Higher education in Russia, 2025. Vol. 34. №6.: 36-57.
- User manual «AI platform for creating virtual agents in education». Moscow: 2026. 19 p.
- Edge D. From Local to Global: A Graph RAG Approach to Query-Focused Summarization / D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, J. Larson // arXiv. 2024. arXiv:2404.16130.
- Han H. Retrieval-Augmented Generation with Graphs (GraphRAG) / H. Han, Y. Ding, C. Liu et al. // arXiv. 2025. arXiv:2501.00309.
- Lewis P. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks / P. Lewis, E. Perez, A. Piktus et al. // arXiv. 2020. arXiv:2005.11401.
- Miao F., Holmes W. Guidance for Generative AI in Education and Research. Paris: UNESCO, 2023.
- Wu S. Retrieval-Augmented Generation for Natural Language Processing: A Survey / S. Wu, Y. Zhang, F. Fei et al. // arXiv. 2024. arXiv:2407.13193.