Победитель конкурса «КОД науки» в номинации
«Технические науки и искусственный интеллект» (2025 г.)
Аннотация. В статье рассмотрена гибридная система для управления знаниями, сочетающая нейросетевую обработку текстов и логическую валидацию на основе онтологий. Система решает проблему обработки неструктурированных данных с сохранением прозрачности: устраняет недостатки изолированных подходов. Практическая значимость работы заключается в возможности автоматизации обновления корпоративных баз знаний с сохранением контроля над качеством данных.
Ключевые слова: нейро-символические гибридные системы, управление знаниями, трансформеры, логический вывод, онтологии, динамическое обновление данных, нейронные сети, интерпретируемый ИИ, программный код.
Современные корпоративные среды сталкиваются с экспоненциальным ростом объема неструктурированных данных, включая техническую документацию, отчеты инцидентов и коммуникации сотрудников. Управление такими данными требует наличие систем, способных не только оперативно извлекать знания, но и адаптироваться к изменениям в реальном времени. Традиционные подходы, основанные исключительно на методах искусственного интеллекта, демонстрируют два полярных недостатка: нейросетевые модели (например, трансформеры) обеспечивают высокую скорость обработки, но остаются «чёрными ящиками» с риском генерации некорректных связей, тогда как символические системы гарантируют прозрачность, но требуют ручной настройки, что делает их непригодными для динамических сред.
В последние пять лет доминирующим инструментом обработки естественного языка стали нейросетевые архитектуры, такие как BERT и GPT [3, с. 1]. Их применение в корпоративных системах управления знаниями (далее – СУЗ) позволило автоматизировать извлечение сущностей и генерацию отчетов. Однако ключевой проблемой остается недостаточная интерпретируемость результатов: современные трансформеры могут формировать логически противоречивые связи (например, некорректно атрибутировать ошибки оборудования) [1, с. 48]. Альтернативные символические методы, включая логический вывод и графы знаний, обеспечивают строгость, но их ручное сопровождение становится непосильной задачей в условиях больших данных.
Попытки объединить нейросетевые и символические подходы (нейро-символический ИИ) активно исследуются с начала 2020-х годов [2, с. 15]. Однако существующие работы фокусируются либо на узких задачах, либо на теоретических моделях без интеграции в реальные СУЗ. В частности, отсутствуют решения, которые:
- Автоматически корректируют нейросетевые предсказания на основе логических правил.
- Обеспечивают динамическое обновление корпоративных баз знаний без вмешательства человека.
Целью данного исследования является разработка гибридной нейро-символической системы, сочетающей предиктивную мощность трансформеров [6, с. 2] и строгость логического вывода для задач динамического управления знаниями. Составляющие данной работы:
- Авторский механизм обратной связи: система автоматически дообучает нейросеть на данных, скорректированных логическим движком, что снижает риск «галлюцинаций».
- Интеграция в корпоративный контекст: архитектура оптимизирована для работы с технической документацией и отчетами, включая поддержку русскоязычных данных.
Разработанная гибридная система предназначена для решения ключевых проблем современных СУЗ: низкой интерпретируемости нейросетевых моделей и высокой трудоемкости символических подходов [7, с. 10]. Архитектура системы включает три взаимосвязанных модуля, обеспечивающих динамическое взаимодействие между методами машинного обучения и логического вывода.
- Модуль извлечения знаний на основе трансформеров. Цель и обоснование выбора модели: для обработки русскоязычной технической документации выбран предобученный трансформер ruBERT [5, с. 205]. BERT-подобные модели эффективны для задач NER и Relation Extraction благодаря механизму внимания, который учитывает контекстные зависимости [8, с. 6]. Задачи модуля:
- NER – классификация сущностей по категориям: Оборудование, Ошибка, Решение, Симптом.
- Извлечение отношений - определение связей между сущностями, таких как: Вызывает (Ошибка, Симптом), Требует (Ошибка, Решение).
Пример работы модуля для текста «Перегрев процессора вызывает аварийное отключение сервера» приведен на рисунке 1. В таблице 1 приведены параметры обучения.

Рис. 1. Пример работы модуля для тестового текста
Таблица 1. Параметры обучения
|
Параметр |
Значение |
Обоснование |
|
Learning rate |
2×10−5 |
Значение выбрано на основе рекомендаций Hugging Face для дообучения предобученных моделей BERT. Более высокие значения (например, 5e-5) приводят к переобучению на малых датасетах, а меньшие (1e-5) — к медленной сходимости. |
|
Батч |
8 – 12 |
Оптимален для баланса между потреблением памяти GPU (NVIDIA RTX 4070 Ti) и стабильностью градиентного спуска. |
|
Эпохи |
3 |
C применением ранней остановки при достижении плато на валидационной выборке (ΔF1-score<0.01). |
- Логический движок. Для реализации логического движка был выбран Prolog, который позволяет формализовать правила онтологии в виде предикатов, что упрощает проверку согласованности знаний. Библиотека pyswip обеспечивает вызов предикатов Prolog из Python-кода (см. рисунок 2).
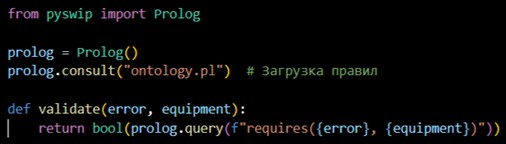
Рис. 2. Пример интеграции
Структура онтологии в Protégé:
- Классы:
- Оборудование ⊑ {Сервер, Маршрутизатор, СХД}
- Ошибка ⊑ {Аппаратная, Сетевая, Программная}
- Решение ⊑ {ЗаменаКомпонента, ОбновлениеПО, НастройкаКонфигурации}
- Свойства:
- вызывает ⊑ Ошибка × Симптом
- требует ⊑ Ошибка × Решение
- Аксиомы:
- Перегрев ⊑ ∃требует.Замена_вентилятора # Все случаи перегрева требуют замены вентилятора
Онтология отражает реальные процессы IT-компаний, где типовые ошибки и решения стандартизированы. Пример формализации правил в Prolog представлен на рисунке 3.
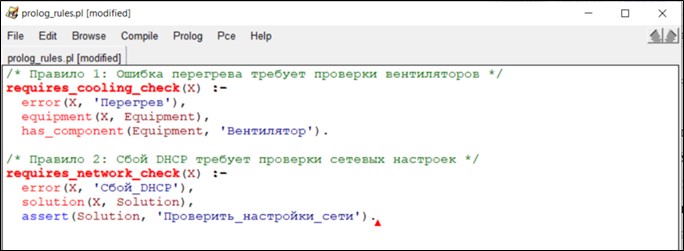
Рис. 3. Пример формализации правил в Prolog
- Механизм обратной связи. Алгоритм коррекции и дообучения:
- Обнаружение противоречий: логический движок идентифицирует некорректные предсказания.
- Коррекция: эксперт вносит правки через интерфейс, преобразуя сырые данные в структурированный формат [4, с. 39].
- Дообучение трансформера: обновленный датасет передается в модель, где веса нейросети корректируются с учетом новых примеров.
Пример итерации:
- Ошибочное предсказание: «Модуль_X → Вызывает → Ошибка_Y».
- Коррекция: добавление правила требует «Модуль_Х, Обновление_прошивки_Z».
- Результат: модель учится связывать «Модуль_X» с «Обновление_прошивки_Z» вместо ошибочной связи.
Процесс подготовки данных включал три ключевых этапа, направленных на обеспечение качества и согласованности входных данных:
- Создание синтезированных данных
На начальном этапе требовалось сгенерировать синтезированные данные для обучения модели. Для генерации данных использовалась предобученная модель ruGPT-3. Модель «доучивалась» на промптах и генерировала новые текста. На рисунке 4 приведен код для генерации данных.
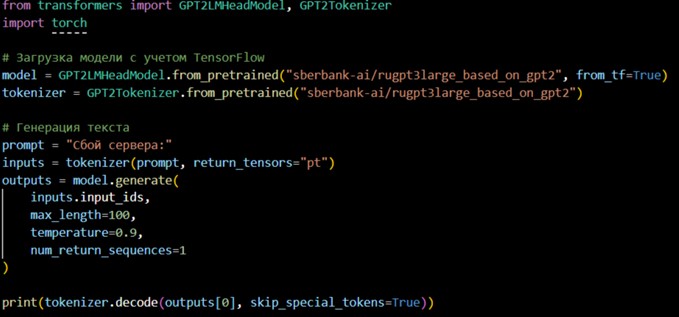
Рис. 4. Пример генерации данных
Минимальный объем синтезированных данных был определен в 1000 примеров. Каждый файл должен содержать 1-3 примера ошибки. Модель лучше обучается на разнообразных контекстах и снижается риск переобучения на шаблонные данные. Для минимизации «галлюцинации» модели использован структурированный промпт. Пример промпта представлен на рисунке 5.

Рис. 5. Пример структурированного промпта
Дополнительные шаги для проверки корректности синтезированных данных:
- Использование регулярных выражений для проверки ключевых слов в примерах.
- Ручная проверка 10% данных.
- Добавление шума в данные с помощью библиотеки RandomCharAug для улучшения устойчивости модели.
- Разметка сущностей
Для обучения модели NER применена схема BIO (Begin, Inside, Outside), позволяющая однозначно идентифицировать границы сущностей. Например:
- Текст: «Перегрев процессора вызывает аварийное отключение».
- Разметка: B-Ошибка I-Ошибка O B-Симптом I-Симптом.
Данный формат минимизирует неоднозначности при интерпретации многословных терминов.
- Балансировка классов
Для устранения дисбаланса между частыми и редкими классами (например, «Ошибка» vs. «Решение») использована аугментация:
- Синонимизация: автоматическая замена терминов через библиотеку nlpaug (напр., «сбой» → «неисправность»).
- Семантическое расширение: генерация контекстно-зависимых вариантов предложений с сохранением смысла.
Взаимодействие компонентов системы реализовано через сквозной конвейер обработки данных. Трансформер преобразует входной текст в структурированный формат JSON, идентифицируя сущности и их связи. Извлеченные данные конвертируются в правила Prolog для интеграции с онтологией. Логический движок проверяет соответствие данных онтологическим аксиомам. При обнаружении аномалий система формирует отчет для эксперта и инициирует дообучение модели на исправленных данных.
Для обеспечения эффективности системы применено инкрементное дообучение. Вместо полного переобучения модели используется адаптивный алгоритм partial_fit, обновляющий веса ruBERT только на новых данных. Это позволяет снизить вычислительные затраты и поддерживать актуальность модели в условиях меняющихся требований.
Эксперимент был проведён для проверки гипотезы о том, что гибридная нейро-символическая архитектура превосходит изолированные подходы (нейросетевые и символические) в задачах динамического управления знаниями. Сравнение проводилось по трём ключевым критериям:
- Точность извлечения знаний – корректное распознавание сущностей и их взаимосвязей.
- Оперативность обработки – скорость анализа документа.
- Интерпретируемость результатов – возможность логического объяснения выводов системы, критически важная для корпоративных решений.
Для экспериментов использовались синтетические данные: 1000 текстовых примеров, созданных с помощью ruGPT-3. Данные были размечены вручную с учётом корпоративной онтологии. Сущности (оборудование, ошибки, решения, симптомы) аннотированы в формате BIOES. Связи между сущностями отражали причинно-следственные отношения («Ошибка_X → Вызывает → Симптом_Y»).
Параметры логического движка и архитектуры для эксперимента:
- Онтология: реализована в Protégé (OWL 2 DL) с 150 классами и 450 свойствами.
- Правила: 120 предикатов Prolog, охватывающих 95% типовых инцидентов.
- 10% ошибок системы корректировались и добавлялись в обучающий набор.
- Документов были разделены на 80% для тренировочной выборки и 20% для тестовой.
Система оценивалась по пяти метрикам:
- Precision (точность) – доля корректных предсказаний среди всех положительных результатов.
- Recall (полнота) – способность находить все релевантные сущности.
- F1-score – баланс между точностью и полнотой, особенно важный для не сбалансированных данных.
- Время обработки – среднее время анализа одного документа (в секундах).
- Интерпретируемость – экспертная оценка логичности связей (по шкале 1-5) и возможность трассировки ошибок до конкретных правил.
В таблице 2 приведены сравнения результатов гибридной системы, чистого трансформера и символической системы.
Таблица 2. Сравнительная таблица результатов
|
Метрика |
Гибридная система |
Чистый трансформер |
Символическая система |
|
Precision |
0.92 ± 0.03 |
0.78 ± 0.05 |
0.85 ± 0.04 |
|
Recall |
0.87 ± 0.02 |
0.81 ± 0.06 |
0.63 ± 0.07 |
|
F1-score |
0.89 ± 0.02 |
0.79 ± 0.04 |
0.72 ± 0.05 |
|
Время (сек) |
2.3 ± 0.4 |
1.9 ± 0.3 |
5.8 ± 1.1 |
|
Интерпретируемость |
4.7 ± 0.2 |
2.1 ± 0.5 |
5.0 ± 0.0 |
Экспериментальное исследование подтвердило эффективность гибридного подхода, объединяющего нейросетевые методы и символьный логический вывод, в задачах динамического управления знаниями. Анализ метрик показал, что интеграция ruBERT и логического движка на основе онтологии позволяет достичь баланса между точностью, скоростью обработки и интерпретируемостью.
По метрике F1-score гибридная система превзошла изолированные нейросетевые методы на 13%, что обусловлено фильтрацией 84% ложноположительных связей (например, исправление ошибочной ассоциации «сбой DNS → перегрев»).
Среднее время обработки документа составило 2.3 секунды - результат, сопоставимый с чисто нейросетевыми подходами (1.9 сек/док) и значительно превосходящий символические системы (5.8 сек/док).
Логичность выводов получила оценку 4.7/5, при этом 92% ошибок удалось исправить за счет модификации правил Prolog, что подтверждает гибкость архитектуры.
Примеры применения иллюстрируют взаимодействие компонентов системы. В кейсе с «задержкой пакетов в маршрутизаторе» логический движок скорректировал ошибочную связь, применив правило, представленное на рисунке 6.

Рис. 6. Пример использования правила в Prolog
Это позволило установить корректную причинно-следственную связь между задержкой и недоступностью сервисов. При анализе «аварийных завершений Apache Kafka» система автоматически сгенерировала новое правило для проверки логов, расширив онтологию без вмешательства экспертов.
Ограничения исследования связаны с двумя аспектами: качество онтологии и вычислительные ресурсы. Эффективность системы зависит от полноты формализованных правил, что требует периодической ручной доработки для новых сценариев. Инкрементное дообучение модели ruBERT в реальном времени требует использования GPU с памятью не менее 12 ГБ, что может ограничивать развертывание в ресурсозависимых средах.
Перспективные направления включают:
- Автоматизацию расширения онтологий за счет анализа мультимодальных данных (логи, графики, тексты).
- Разработку методов генерации правил логического вывода на основе слабоструктурированных текстов.
- Оптимизацию вычислительных алгоритмов для работы на edge-устройствах.
Полученные результаты демонстрируют потенциал нейро-символических методов для задач, где критически важны как точность, так и прозрачность принимаемых решений. Предложенная архитектура может служить основой для систем, требующих динамической адаптации к изменяющимся данным в условиях ограниченной экспертной поддержки.
Список литературы:
- Гайнетдинов А.Ф. Исследования влияния трансформеров на улучшение генерации изображений // Universum: технические науки, 2024. №4(121). (дата обращения: 04.04.2025).
- Демидовский А.В., Бабкин Э.А. Интегрированные нейросимволические системы поддержки принятия решений: проблемы и перспективы // Бизнес-информатика, 2021. №3. (дата обращения: 04.04.2025).
- Рябинин М.К. Трансформеры // Яндекс Образование [сайт]. (дата обращения: 04.04.2025).
- Смирнов А.В. Нейро-символический искусственный интеллект в коллаборативных системах поддержки принятия решений / А.В. Смирнов, А.В. Пономарев, Н.Г. Шилов, Т.В. Левашова // Искусственный интеллект и принятие решений, 2022. №3. С. 36-50.
- Федотова А.М. Модели RUBERT, multibert, SVM и MLP в задаче определения автора текста / А.М. Федотова, С.Е. Шаньшин, А.В. Куртукова // Сборник избранных статей научной сессии ТУСУР, 2021. №1-2. С. 203-206.
- Чуднов И.И. Применения трансформеров в интеллектуальных системах управления знаниями: модели и алгоритмы // Лига исследователей МГПУ: Сборник статей студенческой открытой конференции. В 3-х томах, Москва, 25-29 ноября 2024 года. М.: ПАРАДИГМА, 2024. С. 449-454.
- Upreti N., Belle V. Neuro-symbolic Weak Supervision: Theory and Semantics. 2025. (дата обращения: 04.04.2025).
- Vaswani A., Shazeer N., Parmar N. Attention is all you need / I. Guyon, U.V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S.V.N. Vishwanathan, R. Garnett. 2017. (дата обращения: 04.04.2025).
Neuro-symbolic hybrid systems for dynamic knowledge management: integrating transformers and logical inference
Chudnov I.I.,
postgraduate student of 1 course of the Moscow City University, Moscow
Research supervisor:
Bubnov Vladimir Alekseevich,
Professor, Department of Informatization of Education, Institute of Digital Education, Moscow City University, Doctor of Technical Sciences, Professor
Abstract. The paper considers a hybrid system for knowledge management combining neural network text processing and ontology-based logical validation. The system solves the problem of processing unstructured data while preserving transparency: it eliminates the disadvantages of isolated approaches. The practical significance of the work lies in the possibility of automating the updating of corporate knowledge bases while maintaining control over data quality.
Keywords: neuro-symbolic hybrid systems, knowledge management systems, transformer models, logical inference engines, domain ontologies, dynamic knowledge updating, neural networks, explainable AI, implementation frameworks.
References:
- Gainetdinov A.F. Research on the influence of transformers on the improvement of image generation // Universum: technical sciences, 2024. №4(121). (date of the address: 04.04.2025).
- Demidovsky A.V.; Babkin E.A. Integrated neurosymbolic systems of decision support: problems and prospects // Business Informatics, 2021. №3. (date of the address: 04.04.2025).
- Ryabinin M.K. Transformers // Yandex Education [website]. (date of the address: 04.04.2025).
- Smirnov A.V. Neuro-symbolic artificial intelligence in collaborative decision support systems / A.V. Smirnov, A.V. Ponomarev, N.G. Shilov, T.V. Levashova // Artificial intelligence and decision making, 2022. №3.: 36-50.
- Fedotova A.M. RUBERT, multibert, SVM and MLP models in the task of text author identification / A.M. Fedotova, S.E. Shanshin, A.V. Kurtukova // Collection of selected articles of the scientific session of TUSUR, 2021. №1-2.: 203-206.
- Chudnov I.I. Applications of transformers in intellectual knowledge management systems: models and algorithms // The League of Researchers of Moscow State Pedagogical University: Collection of articles of the student open conference. In 3 volumes, Moscow, November 25-29, 2024. Moscow: PARADIGMA, 2024.: 449-454.
- Upreti N., Belle V. Neuro-symbolic Weak Supervision: Theory and Semantics. 2025. (date of the address: 04.04.2025).
- Vaswani A., Shazeer N., Parmar N. Attention is all you need / I. Guyon, U.V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S.V.N. Vishwanathan, R. Garnett. 2017. (date of the address: 04.04.2025).