Аннотация. В данной статье приводится анализ количественных параметров оценки сложности текста на разных уровнях языка: фонологическом, морфологическом, синтаксическом и лексическом. Кроме того, рассмотрены более сложные статистические показатели, такие как индексы удобочитаемости (тест Флеша-Кинкейда, LIX, FRE) и индекс SMOG. В статье описывается потенциал количественных показателей для создания автоматических программ комплексной оценки сложности текста для дидактических целей.
Ключевые слова: сложность текста, уровни языка, автоматические программы оценки сложности текста, сегментация и токенизация текста, стоп-слова, регулярные выражения, лексическое разнообразие, классификация CEFR, индекс удобочитаемости.
Оценка сложности текстов является одним из важных компонентов в лингводидактике. Именно она позволяет учителям и методистам сделать вывод о целесообразности использования того или иного текста в образовательном процессе, а также оценить работы, написанные обучающимися, понять, насколько они соответствуют заявленным критериям и уровню владения языком. В связи с этим возникает потребность в составлении списка количественных метрик, который позволит создать автоматическую программу для оценки сложности текста на всех уровнях языка: фонологическом, морфологическом, синтаксическом, семантическом. Кроме того, стоит сделать акцент и на более сложных статистических показателях, которые также формируют описательную статистику иноязычного текста.
Таким образом, актуальность работы заключается в систематизации существующих критериев сложности, их классификации по уровням языка и обозначении их практического применения в лингводидактике.
Анализ существующих инструментов
На данный момент рынок мобильных и веб-приложений, посвященных оценке сложности англоязычного текста невелик. Из наиболее популярных по количеству пользователей можно выделить «Text Analyser» и «Text Inspector». Оба ресурса включают в себя оценку сложности текста на лексическом уровне языка (согласно классификации слов по CEFR). Кроме того, «Text Analyser» выводит общую описательную статистику по тексту, а именно, количество слов в тексте, среднюю длину слов и предложений. В приложении «Text Inspector» представлена более полная статистика, так как в нем рассматривается еще и морфологический уровень (номинативность и описательность текста). Однако список метрик, по которым стоит оценивать сложность текста в обоих приложениях не исчерпывающий, так как не рассматриваются такие уровни языка как фонологический, синтаксический и семантический, а также отсутствуют более комплексные показатели, которые были выведены лингвистами и педагогами для универсальной оценки текстов (например: индекс читабельности, коэффициенты Флеша-Кинкейда [5], [6], индекс LIX [7], [8] и другие). В связи с этим возникает потребность в комплексном анализе всех представленных метрик, их систематизации для дальнейшего создания собственного инструмента для анализа сложности англоязычного текста.
Фонологический уровень
На фонологическом уровне сложность отдельно взятого словоупотребления (а также предложения и текста в целом) зависит от абсолютного количества односложных, двусложных, трехсложных и четырехсложных слов и их средних значений в предложении; среднего показателя слогов в словоупотреблении и предложении, общего числа слогов в тексте. Подсчет этих показателей и систематизация позволят педагогам и методистам оценить сложность текста с точки зрения фонологии и понять релевантность его использования в той или иной аудитории и ситуации [7].
Морфологический уровень
Морфологический уровень подразумевает разнообразие грамматических форм. На данном уровне языка проводится деление на знаменательные и служебные части речи, причем на первые из них делается больший акцент в лингводидактике. В связи с этим двумя важными показателями являются номинативность (отношение количества имен существительных ко всем значимым токенам в тексте) и среднее количество существительных в предложении, описательность (отношение количества имен прилагательных ко всем значимым токенам в тексте) и среднее количество прилагательных в предложении. Также стоит обратить внимание на другие знаменательные части речи; такие как наречия, глаголы, местоимения и числительные и посчитать их абсолютное значение в тексте. Кроме того, необходимо провести анализ грамматических форм знаменательных частей речи в контексте и указать их количество, а также отношение к общему числу знаменательных частей речи в тексте (например: дистрибуция по падежам в склонении имен существительных и отношение подобных форм к общему числу существительных в тексте, наличие различных временных форм глаголов и их отношение к общему числу глаголов). Это поможет учителям и методистам сделать вывод о целесообразности использования текстов с теми или иными временными глагольными формами [6].
Синтаксический уровень
Объектами синтаксического уровня служат связи слов в предложении, а также наличие различных синтаксических конструкций. В связи с этим необходимо найти общее количество слов и предложений в тексте, определить среднюю длину слов и предложений, а также количество различных сложных синтаксических конструкций (например: придаточных в предложениях). На основе этого можно сделать вывод о том, подходят ли тексты с выделенными синтаксическими конструкциями определенным возрастным группам, изучающим иностранный язык [6].
Лексический уровень
Одним из основных лексических показателей оценки сложности текста является коэффициент лексического разнообразия (Type Token Ratio, TTR) [1].
![]()
Где N – количество различных слов в тексте.
Коэффициент варьируется от 0 до 1 (где теоретический 0 – это текст, где повторяется одно и то же словоупотребление бесконечное количество раз, а 1 – это текст, где все слова уникальны и не повторяются в тексте). Однако коэффициент лексического разнообразия имеет некорректную интерпретацию при анализе объемных текстов, из-за большого количества служебных и общеупотребительных слов, которые сказываются на результате.
В связи с этим лингвисты ввели скорректированные метрики коэффициента лексического разнообразия, а именно Root Type Token Ratio, RTTR [2]:
![]()
Где N – количество различных слов в тексте.
Также Corrected Type Token Ratio, CTTR [2]:
![]()
Где N – количество различных слов в тексте.
Предлагается использование всех трех вариаций коэффициента лексического разнообразия, а также ограничение первоначального TTR в расчете на 1000 токенов.
Кроме того, на лексическом уровне стоит отметить дистрибуцию слов и коллокаций по уровням владения иностранным языком (согласно классификации CEFR) и определить общее количество слов и коллокаций уровней А1, А2, В1, В2, С1 в тексте.
Семантический уровень
Семантический уровень анализа показывает, к каким темам относится определенный текст. В некоторых случаях выбор темы обуславливается исходя из возрастных особенностей обучающихся и их уровня владения иностранным языком. Следовательно, семантическая дистрибуция текстов (сравнение значимых токенов текста с датасетами по топикам) и определение самых популярных (частотных) тем позволит оценить сложность текста с точки зрения тематической принадлежности (сложность текста увеличивается при возрастании количества микро-тем) [3].
Статистические метрики
Данные статистические критерии позволяют определить, насколько текст удобен для чтения. Первый их них – это индекс удобочитаемости Флеша (FRE), метрика, показывающая сложность восприятия текста по 100-балльной шкале (где 0 – это самый сложный текст, который способны осилить выпускники профильных вузов, а 100 – самый легкий, доступный для чтения обучающимся начальной школы). [4]. Высчитывается по формуле:
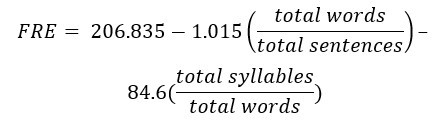
Где total words – общее количество слов в тексте, total sentences – общее количество предложений в тексте, total syllables – общее количество слогов в тексте.
Другая формула – тест Флеша-Кинкейда (FKGL), метрика, позволяющая определить потенциальный уровень подготовки обучающихся, для которых предназначен данный текст. Рассчитывается по формуле:
![]()
Где total words – общее количество слов, total sentences – общее количество предложений, total syllables – общее количество слогов.
Коэффициенты перед дробями были определены экспериментальным путем и соответствуют английскому языку (для другого естественного языка коэффициенты будут варьироваться).
Еще один показатель удобочитаемости – это индекс LIX, высчитывающийся по формуле [4]:
![]()
Где N words – общее количество слов, N sentences – общее количество предложений, N long words – общее количество длинных слов (слов длиннее шести букв). В результате получается положительное число (чем больше итог, тем сложнее текст).
Индекс SMOG показывает количество лет, которое необходимо выделить на изучение иностранного языка для понимания данного текста:
![]()
Для вычисления индекса SMOG необходимо рассчитать количество многосложных слов (тех, которые имеют 3 и более слогов) в 30 предложениях (выборка предложений должна быть репрезентативной, поэтому необходимо рассмотреть 10 предложений из вступительной части, 10 из основной и 10 из заключительной части), затем рассчитать квадратный корень из этого количества слов и округлить до ближайшей десятки, после этого прибавить 3. В итоге получается число, приблизительно эквивалентное времени, которое необходимо выделить на изучение иностранного языка для полного понимания содержания текста.
Практическое применение
Данные метрики и показатели могут быть применены для написания автоматических программ по анализу сложности текстов с помощью технологий программирования. Для этого необходимо провести предварительную обработку текста: сегментировать текст на предложения, выделить токены, а также избавиться от стоп-слов (служебных частей речи: предлогов, союзов, частиц, артиклей, междометий), знаков препинания и числовых обозначений. Затем необходимо провести лемматизацию (приведение знаменательных частей речи к начальной форме). После этого этапа возможен подсчет описательных статистик и метрик текста на каждом уровне.
На фонологическом уровне необходимо использовать функцию определения слогов в слове: для этого нужно подсчитать количество слогообразующих элементов, для английского языка это будут гласные и сонорные /l/, /m/, /n/, стоящие в конце слова, и учесть примеры диграфов (звуков, которые на письме выражаются двумя гласными буквами), случаи употребления гласных букв на письме, которые не произносятся (например: буква «е» на конце многосложных слов по типу «cake», «lake», «snake» и других) и заимствования из других языков в английский с особым произношением.
На морфологическом уровне необходимо применить функции частеречной разметки текста, на синтаксическом – функции определения количества слов и предложений, а также определить регулярные выражения для извлечения примеров использования определенных грамматических конструкций.
Для лексического и семантического уровней будут нужны размеченные датасеты с классификацией наиболее общеупотребительной лексики по уровням владения языком и тематике.
Для расчета коэффициентов Флеша-Кинкейда, метрик LIX и SMOG достаточно определить главные описательные статистики текста (количество слогов, слов и предложений в тексте, многосложных слов).
После расчета всех метрик текста, распределенных по уровням языка, стоит визуализировать результаты в виде таблиц, круговых и столбчатых диаграмм, что позволит методистам и учителям наглядно ознакомиться со сложностью текста на разных уровнях и сделать вывод о целесообразности использования данного текста в образовательном процессе.
Список литературы:
- Захарова Е.Ю., Савина О.Ю. Лексическое разнообразие текста и способы его измерения // Вестник Тюменского государственного университета. Гуманитарные исследования. Humanities. 2020. Т. 6, №1(21). С. 20-34.
- Казачкова М.Б., Галимова Х.Н. Лексическое разнообразие текста как параметр сложности текстов // Вестник Марийского государственного университета. 2021. Т. 15, №3(43). С. 384-390.
- Караулов Ю.Н. Русский язык и языковая личность. Изд. 7-е. М.: Издательство ЛКИ, 2010. 264 с.
- Методика определения возраста автора текста на основе метрик удобочитаемости и лексического разнообразия / А.А. Соболев, А.М. Федотова, А.В. Куртукова [и др.] // Доклады Томского государственного университета систем управления и радиоэлектроники. 2022. Т. 25, №2. С. 45-52.
- Микк Я.А. Методика измерения трудности текста // Вопросы психологии. 1975. №3. С. 147-155.
- Солнышкина М.И., Кисельников А.С. Сложность текста: этапы изучения в отечественном прикладном языкознании // Вестник Том. гос. ун-та. Филология. 2015. №6(38). С. 86-99.
- Kupriyanov R.V. Cognitive complexity measures for educational texts: Empirical validation of linguistic parameters / R.V. Kupriyanov, O.V. Bukach, O.I. Aleksandrova // Russian Journal of Linguistics. 2023. Vol. 27, №3.: 641-662.
- Morozov D.A. Text complexity and linguistic features: Their correlation in English and Russian / D.A. Morozov, A.V. Glazkova, B.L. Iomdin // Russian Journal of Linguistics. 2022. Vol. 26, №2: 426-448.
Quantitative criteria for evaluating text complexity
Polyakov A.M.,
bachelor of 4 course of the Moscow City University, Moscow
Research supervisor:
Zoidze Ella Amiranovna,
Associate Professor of the Department of English Studies and Cross-Cultural Communication of the Institute of Foreign Languages of the Moscow City University, Associate Professor of Philological Sciences, Associate Professor.
Annotation: The article deals with the analysis of quantitative metrics of text complexity evaluation on different linguistic layers: phonological, morphological, syntactic and lexical. Moreover, statistical features like the readability index (Flesсh-Kincaid readability test, LIX, FRE) and SMOG index are mentioned. Furthermore, qualitative metrics are viewed from the perspective of methodical potential in teaching English.
Keywords: the text complexity, linguistic layers, automatic programs of text complexity evaluation, segmentation and tokenization, stop-words, regular expressions, lexical diversity, CEFR classification, readability index.
References:
- Zakharova E.U., Savina O.U. Lexical diversity of texts and ways how to measure it // Tumen State University Herald. Humanities. 2020. Т. 6, №1(21).: 20-34.
- Kazachkova M.B., Galimova H.N. Lexical diversity as a text evaluation metric // Vestnik of the Mari State University. 2021. Vol. 15, №3(43).: 384-390.
- Karaulov U.N. Russian and the language personality. Pub. 7-е. Moscow: Publishment LKI, 2010. 264 p.
- The method of detecting the author’s age according to the indexes of readability and lexical diversity / A.A. Sobolev, A.M. Fedotova, A.V. Kurtukova [and others] Proceedings of Tomsk State University of Control Systems and Radioelectronics. 2022. Vol. 25, №2.: 45-52.
- Mikk Ya. A. The methodology of evaluation text complexity // Psychology questions. 1975. №3.: 147-155.
- Solnyshkina M.I., Kiselnikov A.S. Text complexity: education steps in domestic applied linguistics // Tomsk State University Journal. Philology. №6(38).: 86-99.
- Kupriyanov R.V. Cognitive complexity measures for educational texts: Empirical validation of linguistic parameters / R.V. Kupriyanov, O.V. Bukach, O.I. Aleksandrova // Russian Journal of Linguistics. 2023. Vol. 27, №3.: 641-662.
- Morozov D.A. Text complexity and linguistic features: Their correlation in English and Russian / D.A. Morozov, A.V. Glazkova, B.L. Iomdin // Russian Journal of Linguistics. 2022. Vol. 26, №2.: 426-448.